
I have covered some basic idea of knowledge (expert system) engine, including the Pros/Cons here Knowledge Engine. This time, I want to take one more step and use it in a real life backend service.
It is very useful for handling long running operation with one/several remote calls:
- It doesn’t require operation wise locker
- It can handle cancel easily (just change the target state)
- It can handle internal retry easily
It doesn’t work very well if all the data models are closely linked together, as it needs to load all related info into the workflow engine. If everything is linked, we will end up with dumping everything into the workflow for each single operation, which leads to serial processing.
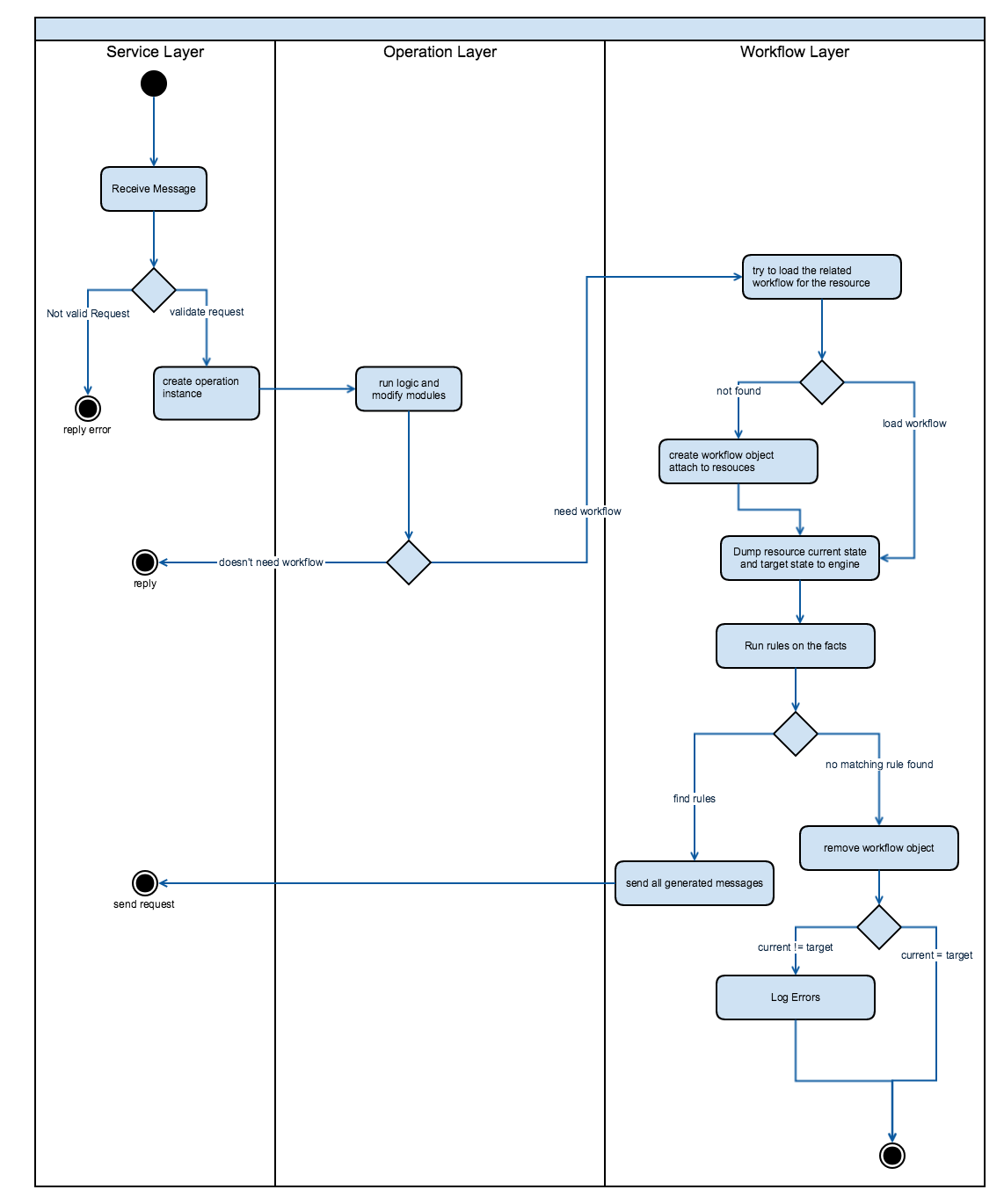
Concept
The service will work as follows:
- Service defines a set of data models as usual
- Each operation just set the current/target state of the data model
- By the end of the operation, service dumps all the facts of the current data + related data into workflow engine
- Workflow engine will find the correct message to send based on those factors
- Service only issues “ACK” after receiving the request. Call should query the model state to see the current progress
Workflow Diagram
Avoid Conflicts among different operations
Each resource can only be executed in one workflow to avoid conflicts, i.e.,
- service receive a call for attach_public_ip, it creates DB record for attachment, set the initial state to ‘created’ and target state to ‘provisioned’
- it issues calls to network and wait for the response
- if it gets a call for detach_public_ip, it just updates the target state to ‘deleted’ and do nothing
- when the response from network arrived, the state of the public_ip will become “provisioned” (or “partially_provisioned” if there is an error). By the end, the rules will be re-evaluated and another call will be issued to destroy the resource
Error Handling and Retry
The error count is kept on operation level for handling retries. Each operation can define its own max retry count. If an operation succeeds, the error count will be reset. i.e:
- on provision public_ip, we will call network_server().publicip_create,
- on the response handle operation, if the response is error, service will record the error, increase error count and won’t update the current/target state
- workflow engine will issue the same request again based on current state
- if the error count exceeds the MAX limit defined on the operation, the state of the resource will be marked with ‘broken’ and not retry will be issued
- if retry succeeds, the error count will be reset to 0 so the next operation in the workflow won’t be affected
Rollback support
This is usually not useful but can be easily supported using the same concept:
If we want to implement rollback on error, we can add one more field to base table “rollback_state”(or “state_state”). If we reach max error count, instead of moving the object to ‘broken’ state, service will copy “rollback_state” into “target_state”.
Workflow engine should take care of how to correctly move the object back to the desired state.